Writing a script in Python
By trade I am not a software developer, but I find it interesting enough to sink hours of my life into. As a hobbyist I have been picking up coding more and more just because of the usefulness of being able to make a custom script for a specific purpose when I need it.
Finding a Purpose and Filling it
Being a practical person who learns best by filling a need I was faced with a unique problem. For those who don't know, I am one of the Senior Staff members over at TF2Maps.net and over the past year I have been using my skills learned in college to help keep the place running. I need to put that degree in Computer Networking to use after all. With that, I also use the need of keeping the place physically functioning to learn more.
With that comes the purpose I am trying to fill with this script. On TF2Maps.net we have this thing called maps, they are levels to the video game Team Fortress 2 and we are a community that focuses on the creation of these levels and everything needed to do so. Once a year we try to feature the best community made maps from that year or prior years if we missed something, let's call these featured maps. We also run two servers for playing Team Fortress 2 on. We want to be running these featured maps on these two servers, it is also important to know we have to configure the servers to run these maps using what is called a mapcycle.txt file, each file in that file represents a map that is in the "rotation". So what's the problem? There's a lot of maps, around 200 or so, and I would have to download each one of those maps, unzip or decompress it if it's like that, add it to the mapcycle.txt on each server, and then upload the map to each of the servers. That's a lot of work! Let's automate it.
Analyzing Options
There's a couple of options for what we could do. We could use Xenforo's REST API to directly query the forums database for the file to download locally, I have the ability to make an API key since it is locked by default. We could use a Python library for scraping html pages, this would require no API tokens. I think for this it makes more sense to use a scraper since that doesn't require any database access.
The next thing to analyze is if I want this script to be something that runs on a server or not. I think for the time being it makes more sense to have this be a local script that I can run on my machine since I am developing it.
Looking at The Basics
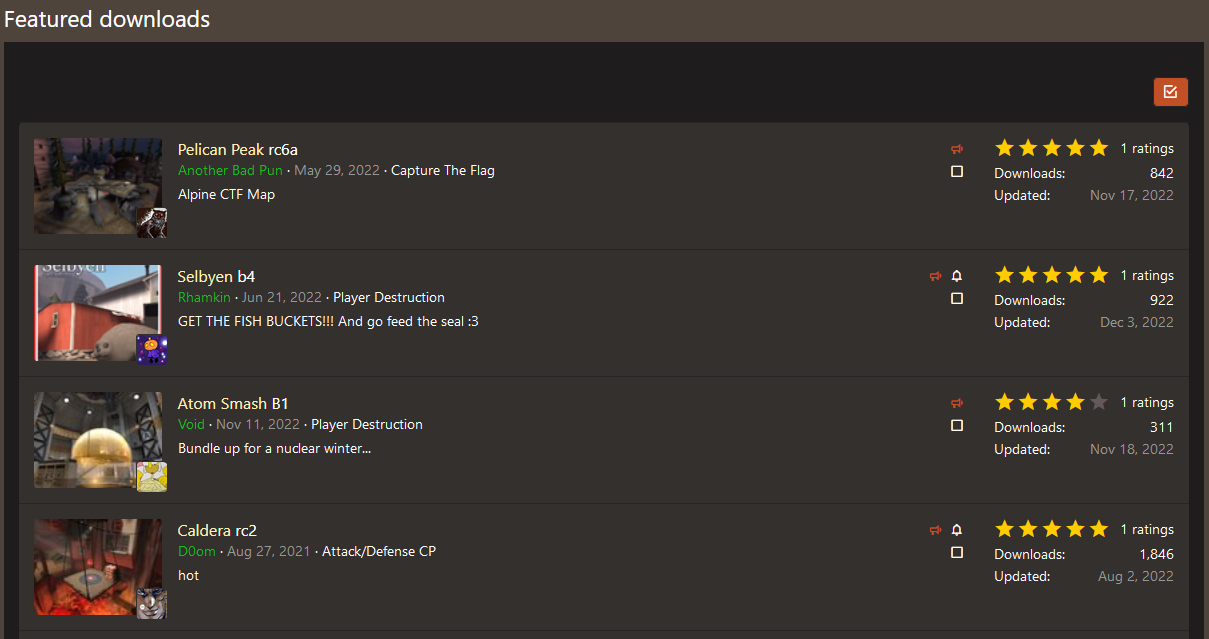
Now I need to figure out my starting point. Our featured maps page, as seen below, provided me with some useful information believe it or not.

The featured maps page is a list if you think about it. Unordered but still a list. This list doesn't provide us with download files, but it provides us with means of getting those download files. Shown below is the download page for that specific map which we can use in the script.
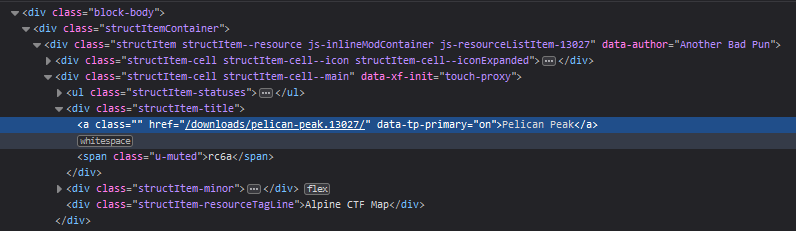
Parsing html files in Python isn't really native so I had to use a third-party library for this. BeautifulSoup4 is the most current version of a html scraper I've seen used before. With BS4 I can look for specific html elements and grab their associated values. Now that I have the list assembled in some order I can use each one of those links to point me to a download page for that map. On the download page it's a similar story where the only useful thing to me is a link hidden in a button. Grab it with the webscraper and download the file locally.

I wasn't sure how to approach this so I looked online and found someone else's solution and modified it to my needs. I'll take the URL that I got earlier and the destination on my local system where to put the file for manipulation if needed.
async def download_file(link, destination):
async with httpx.AsyncClient() as client:
response = await client.get(link)
with open(destination, "wb") as file:
file.write(response.content)File Manipulation
There are a couple of challenges with downloading the map files from about 150+ different people. Everyone uploads them differently! Some put their map files plus other stuff into a zip file, some are in a bz2 archive, and some are just the straight bsp's. I also need to sort out non-map featured content and mvm maps since those are put on their own server. This was something I had to sort through manually before, let's automate it. Because there are only three file types I am dealing with here this feature can be rather simple. I can just check if the file ends with one of the three specific filetypes and modify it if needed.
maps = ['arena_', 'cp_', 'ctf_', 'koth_', 'pass_', 'pd_', 'pl_', 'plr_', 'sd_']
#filter for mvm maps
if downloaded_filename.startswith(tuple(maps)):
if downloaded_filename.endswith(".bsp"):
#to things
#bz2 check
if downloaded_filename.endswith(".bz2"):
#decompress and do things
#zip check
if downloaded_filename.endswith(".zip"):
#unzip and do thingsNow I can start messing with the files specifically. The zip file was the trickiest one to write as there were a bunch of edge cases I had to deal with. Different map authors have different standards, some put just their map into the zip file and nothing else while others put their map and other assets plus a readme.txt file. I had to filter through all this stuff and look for just the bsp. When I was getting the filename I decided to split it by slashes and look for the bsp that way and only extract that and discard the rest.
async def unzip_file(filepath, downloaded_filename):
global bsp_file_name
with ZipFile(filepath) as originalzip:
zipcontents = ZipFile.infolist(originalzip)
for file in zipcontents:
#check for bsp in folders
if file.filename.endswith('.bsp'):
#this is only for mappers who put their map in a folder in a zip
if '/' in file.filename:
desired_file = file.filename.split('/')
#get it
with open('maps/' + desired_file[1], 'wb') as fileoutput:
fileoutput.write(originalzip.read(str(file.filename)))
#set this value for bz2 compression later
bsp_file_name = str(desired_file[1])
else:
with open('maps/' + file.filename, 'wb') as fileoutput:
fileoutput.write(originalzip.read(str(file.filename)))
#set this value for bz2 compression later
bsp_file_name = str(file.filename)
#remove zip file
os.remove(os.getcwd() + '/maps/' + downloaded_filename)Similar to the zip files I had to extract the bsp from the bz2 file. Luckily bz2 is used on the fastdl server so the files that used this were standardized. Fastdl is what serves the player the map if they do now already have it downloaded, this is important for later.
async def bz2_decompress(filepath, downloaded_filename):
global bsp_file_name
with bz2.BZ2File(filepath) as f:
data = f.read()
newfilepath = filepath[:-4]
open(newfilepath, 'wb').write(data)
bsp_file_name = str(newfilepath).split('/')[-1]
#remove bz2 after extracting
os.remove(os.getcwd() + '/maps/' + downloaded_filename)Now that all the files are downloaded and the bsp's are exported I can add them to the mapcycle.txt file for use on the servers. This can be a very simple function as it's only writing to a text file and nothing more.
async def add_to_mapcycle(mapname):
#print to mapcycle file
with open("mapcycle.txt", "a") as f:
splited = mapname.split(".")
f.write(splited[0] + "\n")I also decided that I would compress the maps into a new folder in their bz2 format for the fastdl server to save me time later on. I could have copied the files that were already bz2 but decided it was easier to just decompress and then compress again.
async def compress_file(filepath):
print(f'Compressing {filepath} for redirect.')
output_filepath = os.getcwd() + '/compressed_maps/' + f"{filepath}.bz2"
with open('maps/' + filepath, 'rb') as input:
with bz2.BZ2File(output_filepath, 'wb') as output:
shutil.copyfileobj(input, output)
return output_filepathConclusion
Writing scripts is useful! This was a challenging script to write as I haven't messed with file decompression before. I hope to add the ability to auto upload them to the servers too but didn't want to do that for this release. BS4 is a very cool library for python and made making this script a lot easier. Thanks for making it this far, here's the source code.